In this presentation from the 2021 Typefi Standards Symposium, Kathryn Miller, Publishing Services Librarian at NIST, discusses how the NIST Research Library is planning to pivot from PDF-only publishing to publishing multiple accessible formats including HTML, EPUB, and DAISY XML.
“It has been a common complaint over the last few years from NIST employees and industry partners that our reports are only published as PDFs, and not available in standards-specific XML for reusability, discoverability, and ability to store in repositories.”
“The Library decided that the same efforts should be applied to the NIST Technical Series publications in order to meet the demands of our audience and provide multiple, accessible options for users to read our publications.”
Transcript | Q&A | Presenter
Transcript
| 00:00 | Multiplatform Standards and Guidelines Publishing at NIST |
| 00:53 | About NIST |
| 01:30 | Disclaimer |
| 02:08 | NIST Technical Series publications |
| 03:29 | PDF isn’t enough |
| 05:08 | Computer Security Publications Pilot |
| 08:36 | Accessibility and inclusivity |
| 10:36 | What’s next? |
Multiplatform Standards and Guidelines Publishing at NIST (00:00)
KATHRYN MILLER: I’m Kathryn Miller and I am the Publishing Services Librarian at the National Institute of Standards and Technology, or NIST, in Gaithersburg, Maryland. I want to thank Chris Hausler for inviting me to talk to you all today at the Typefi Standards Symposium.
My work at NIST includes managing the production, dissemination, bibliographic control, and impact assessment activities of the NIST Technical Series publications.
I’m going to talk to you all today about how we are planning to pivot from PDF-only publishing to publishing multiple accessible formats including HTML, EPUB, and DAISY XML.
I’m also going to turn off my camera for the rest of this presentation, but I just wanted to give you a glimpse at the face behind the voice.
About NIST (00:53)
NIST is a nonregulatory agency of the United States Department of Commerce.
The NIST mission is to promote U.S. innovation and industrial competitiveness by advancing measurement science, standards and technology in ways that enhance economic security and improve our quality of life.
The Information Services Office, or NIST Research Library, supports and enhances research activities of the NIST scientific community.
Disclaimer (01:30)
Please note the following disclaimer as I will mention commercial software products in this talk:
Certain commercial equipment, instruments, or materials are identified in this paper in order to specify the experimental procedure adequately. Such identification is not intended to imply recommendation or endorsement by NIST, nor is it intended to imply that the materials or equipment identified are necessarily the best available for the purpose.
NIST Technical Series Publications (02:08)
One of NIST’s responsibilities is to develop industry standards and guidelines, which are published as NIST Technical Series publications.
The NIST Research Library has the unique responsibility for publishing the NIST Technical Series and archiving legacy publications. Here you’ll see the first Technical Note we published in the 1950s, as well as two recent high-impact computer security publications:

The NIST Technical Series publications are highly utilised by the Federal Government, academia, and industry practitioners. From 2018 through 2020, approximately 19,000 publications were downloaded by over 24 million unique users. More than half of the downloads are NIST computer security publications, which include management, administrative, and technical standards and guidelines for securing federal information and information systems that is not national security-related. They are also widely used in the private sector.
PDF isn’t enough (03:29)
Most of the Technical Series publications are only available as PDFs. A few publications, including all the Cybersecurity Practice Guides, are available in HTML. However, the authors are responsible for creating the HTML themselves and hosting it on their own web spaces. The PDF published by the Library is the version of record.
It has been a common complaint over the last few years from NIST employees and industry partners that our reports are only published as PDFs, and not available in standards-specific XML for reusability, discoverability, and ability to store in repositories.
NIST has made great strides in making NIST data and software both digitally accessible and machine readable on data.gov and data.nist.gov.
Here you see an example of a landing page on data.nist.gov for a NIST software program, and the metadata, including the access link, as a JSON file:

The Library decided that the same efforts should be applied to the NIST Technical Series publications in order to meet the demands of our audience and provide multiple, accessible options for users to read our publications.
Computer Security Publications Pilot (05:08)
In 2019, the NIST Research Library began a pilot to publish a sample of high-impact computer security publications in multiple formats for accessibility, reusability, discoverability, and ability to store in repositories.
After attending talks and performing marketing research, we found that NISO STS provided the structure needed to convert these computer security guidelines and standards from the original Microsoft Word documents to XML. The XML would then be used to create PDF, HTML, EPUB, and DAISY XML versions of the publications.
After a public request for proposal, or RFP, process, we chose eXtyles to convert the Word document to NISO STS and Typefi to convert the XML to the final formats that will be hosted on our publications server. The DOI for each publication will point to the HTML, with the option to download other formats. The PDF will remain the version of record.
NISTIR 8241 PDF
While the outputs created by eXtyles and Typefi for our pilot are not publicly available yet, I will show you a sample of the PDF and the HTML. Here is how our publication cover pages look in PDF format:

NISTIR 8241 HTML
And how the same publication will be rendered in HTML:
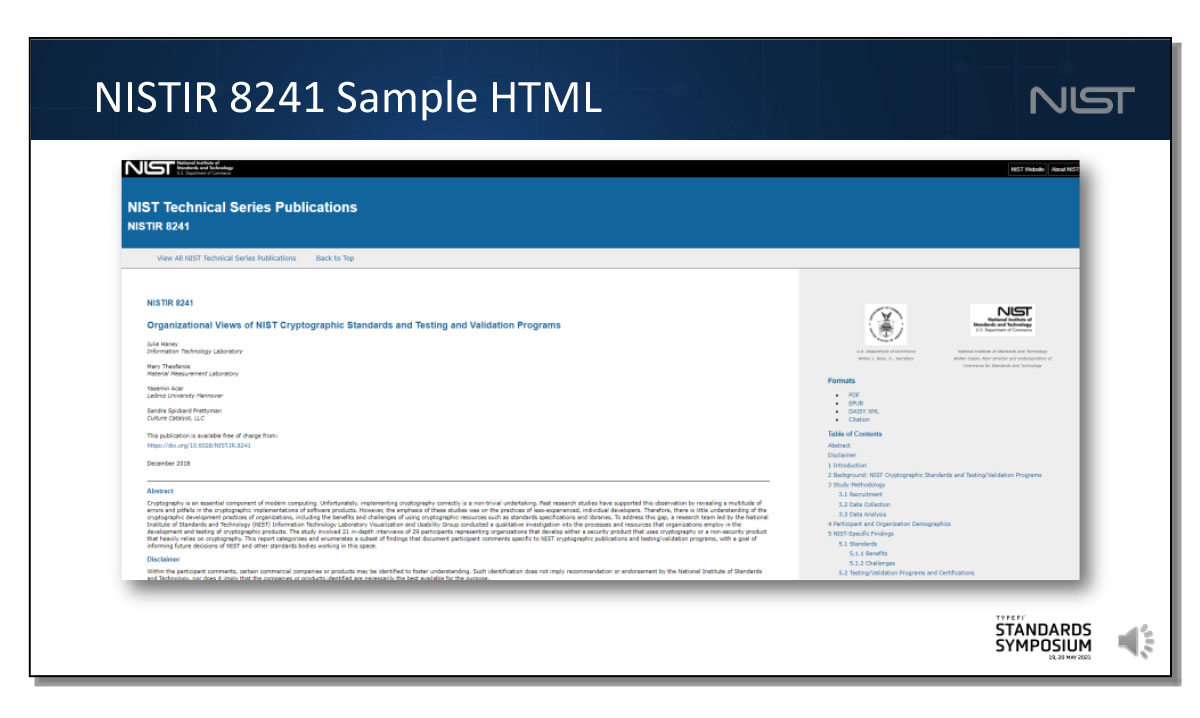
These HTML pages will be hosted as separate files on our publications server as we do not have a robust content management system to work with, but that is a goal for the, probably far, future.
The Process
You’ve seen the sample outputs, but you’re probably wondering about the conversion process of older, yet very important, standards publications.
As you might guess, some of our publications don’t fit into the traditional standard format, so we had to work with eXtyles to fit our content into NISO STS the best we could. This included making use of the notes elements for metadata such as authors, disclaimers, and the agency information.
This is why we started with a sample of publications, and we made an effort to choose a variety of publications with tables, images, equations, reference lists, and author-created formatting issues that somehow made it into the final publication.
This process taught us that our publications are not standardised, even though we have templates.
Decisions were made as part of this process that will hopefully help us standardise future publications and give us leverage to require authors to use templates.
So lesson learned, our standards publications are not actually standard, but now we know and we can get there in the future.
Accessibility and Inclusivity (08:36)
So why are we doing this? Besides the obvious reason that our users want standards and guidelines in multiple formats, we are committed to providing accessible and inclusive research content.
As Guy van der Kolk told me in a conference call a few months ago, the best solution to publishing accessible content is to commit and provide options. So, while we may have placeholder alt-text for some of our older content as we continue to develop this publishing program, the decisions we’ve made during this process hopefully show that we are committed to providing accessible content. The multiple formats will allow our standards content to be read and ingested by a variety of people and programs.
We do realise that this commitment isn’t perfect. For example, DAISY XML can’t handle MathML, so the equations for that will have to be exported as images with alt-text that points users to the EPUB format for a full description. But we know that DAISY is still utilised by assistive devices, so we need to provide it as an option.
Accessible content also ensures that we remain committed to inclusivity in standards documents. NIST recently published guidelines on using inclusive language in standards activities, in NISTIR 8366, and the Technical Series publications author instructions have a section on how to write inclusively and avoid biased and harmful language. If we are encouraging our authors to write inclusively, we need to be inclusive with regards to publishing formats and platforms.
What’s next? (10:36)
So, what’s next? We still have a lot to do, including finishing up the DAISY XML process.
Additionally, we need to do a full content review of the XML to make sure we didn’t introduce any errors during the Microsoft Word to XML transformation. We are going to work with the authors and subject matter experts on that before we make any of these formats publicly available. Any issues we discover during that review will be issues with the Microsoft Word document that can be fixed with removing “fancy” formatting or simply restructuring tables.
Once the sample of Computer Security publications is published, we will review the work done so far, and write procedures to implement this publishing process for all NIST Technical Series publications.
We publish anywhere from 200 to 300 publications a year, so our plan will require a lot of cooperation from our authors and managing expectations with regards to publishing timelines.
But we are really excited by how close we are to finishing this pilot!
I want to thank all my colleagues in the Library who have helped with this process so far. I do want to make special mention of my colleagues Karen Wick, Andrea Medina-Smith, Kate Bucher, Jim Foti, and Kathy Sharpless for their continued support and guidance on all publishing matters; and Sharmon Hawkins for guiding me through the RFP and Acquisitions process for the software needed to make this happen; and my former colleague Kim Tryka for helping me put this idea on paper back in 2017.
Thank you for your time today.
Q&A
What’s the average length of your publications?
Our publications vary from hundreds of pages to five pages. I would say the average length is somewhere around 80 pages, maybe.
How large is your team?
Right now, for the publishing part, it’s just a two and a half of us doing this.
How long did the RFP process take and how many suppliers did you look at?
It’s been a very long process; I actually don’t remember the dates. I know that I presented this project at NIST around 2017, I think the RFP was put out in 2018 or early 2019, and then it was awarded in summer of 2019, I think. There was only me and one other person working on this at the time.
We had to do two separate RFPs—one for the Word to XML conversion and one for the XML to the other formats. If one vendor could do all of them, that was fine too. I think we got about six or seven responses that I was able to look at. I’m not sure how many responses we actually got because they have to go through a checklist before they get to the library, but we looked at a lot of different vendors.
What was your biggest surprise about your non-standard standards?
I think the biggest surprise was around templates. A few standards were older publications, so I knew that the formatting was going to be a little interesting, but some of them were newer and, while we’ve had templates for a while, I guess my biggest surprise was that people weren’t actually using the templates.
When I started working with eXtyles, especially, and I sent them our samples and the templates, I was like, “Oh yeah, they should all be in the template format,” and they replied, “Not really.” So that was a surprise.
Our process had just been visually checking the final PDF from the authors up until now—we didn’t do a lot of deep investigation into the Word documents. I think that was my biggest surprise and something that I know that we’re going to have to work on with training our authors going forward.
How long do you think it’ll take you to convert all 19,000 documents? How will you prioritise which standards get converted first?
One of the first business decisions that we made was that we were not going to convert our back catalogue of 19,000 publications. We have been asked—especially for some of the higher impact publications—if we can do it on a case-by-case basis, and we need to set some guidelines for deciding whether or not we can convert older publications. We haven’t figured that part out yet, but we do know that we are not going to be converting all 19,000 because there’s no way we could possibly do that without sending them to an external vendor to do it themselves.
However, once this starts, everything new that we publish will be using this process. We will be requiring the authors to use our template and then hopefully if they adhere to that, it will all run a little bit smoother.
We wanted to do these older publications because we knew there were going to be issues, especially with how the authors write and use their Word documents for these guidelines, and so we kind of just wanted to deal with all of that at the beginning and see what we were up against.
Will other NIST Technical Series publications that have already been published, be given the option to have their publications converted using this process?
Yeah, so that’s the guidelines I was talking about. We have to come up with a decision-making process, a decision tree, that will probably be based on their use—we track citations and downloads etc., so that’ll probably be a factor—then finding out what the agency wants and what their priorities are. Which is all cybersecurity—it’s a huge priority—so I’m assuming that most of the cybersecurity publications will get the chance to be converted into these formats.
How much time will this process take for each publication?
I don’t know how much time this is going to take for each publication, because we’ve been working with these weird documents that have all these formatting issues. Hopefully for new publications it’ll be quicker if the authors use the templates and follow our instructions. So I don’t know how long it’s going to take, and I know to implement it this wide, you’re going to need more people which will be part of the implementation recommendations that I’m going to write up. A key thing that keeps coming up is that it relies on them—the content and the authors—to follow the instructions and for us to educate them on why they need to write well-structured and accessible documents.
What do you do with publications that are authored in formats other than Word? Do you have content that comes in from LaTeX or FrameMaker?
Another hurdle that we’re going to have to overcome is that a fair number of our publications are actually authored in LaTeX. NIST has a subscription to Overleaf, an online collaborative authoring tool for LaTeX, and a lot of our authors use that to author their publications. So we have templates in there, but it just produces a PDF.
I know there are some tools out there that can convert LaTeX to XML, and I’ve used them, but they’re not great. I’m kind of hoping that maybe Overleaf will have an export option for LaTeX, but until then, we are going to have to figure out what to do with those PDFs, because right now we don’t have a plan for them. We’re focusing on Microsoft Word because I think maybe 85% of our publications are in Microsoft Word and then the rest are in LaTeX. So that’s not an unsignificant number. I haven’t yet looked at converting PDF to XML, but it’s a great possibility. We’ve definitely been focused on the Microsoft Word workflow.
Do you think that the authors, who are used to having creative freedom, are going to adapt well to a more ‘fixed’ workflow with templates?
I think it’s going to be difficult. We have authors and researchers that are in different fields—because each of our labs focuses on a different area in science and technology—and some of them are accustomed to writing standards documents for other organisations and they understand the direction that we’re going in, while others are not.
So I think it’s going to take a lot of education and it’s definitely going to vary from lab to lab. How much we have to do with managing expectations and training will vary as well. I know that’s no small feat and that’s going to be a huge part of the process that we write to implement, and it’s going to take cooperation from their management too at every step of the review process.
I know people have different opinions about formatting and how they want their documents to look. So it’s tough, but I think we can get there once they realise what the benefit of the end product is. I think we just have to keep pushing what the benefits to them will be.
The outreach that the library does and the training that the library does for other things can be applied in these situations too. I don’t expect it to be perfect, but I do think that we can do better, and we can educate the authors and the content creators better, to help us help them in the long run. I don’t think everybody is going to do it perfectly all the time. I don’t think that most people will do it perfectly all the time. It’ll take time, but we’ve seen that our authors can change and adapt, if we push hard enough.
What is NIST’s commitment to accessibility? What accessibility features are you building into your products?
This is definitely a priority and it’s definitely focused on web accessibility. At NIST we have a team of information coordinators who are responsible for the web content for each of our labs, and they’re required to take training on 508 compliance, accessibility and web pages. We’re a government institution, so it kind of has to be a priority by US law, but it’s always been a priority for the PDF publishing, but I think this has given us an opportunity to look at what we’re doing and how we can do it better.
That was one of the key drivers to this decision, that this content is really important and is used by a lot of people, so we have to be inclusive of everybody and make the content accessible to everybody. The machine-readable part of all this was really attractive to those who are already in the NIST data publishing world, because that’s really been a priority for a while—making all of our data and software, machine-readable, findable, and available to the public.
In terms of what accessibility features we’ve included, we have always asked and required authors to put alt text in for their images and tables, but we don’t have the resources to follow up if they don’t do that. So now, with the new templates and this new process—whenever we implement it—alt text is going to be required, including for equations (if they’re images).
Our templates have had these requirements set up – they’re structured, tell you what headings to use, tell you to put alt text in for your tables and images, it has tips about which colours to use for figures, and tells you not to use colours in tables to mean something, unless you have text that also says the same thing as the colour, things like that.
But like I said, we just haven’t really been able to follow up and see if authors are actually following those instructions. So now with our commitment and more resources, we will be able to make sure that authors are following those instructions which may mean delaying their publication, whereas before it was very quick once they sent it to us, we put it up very quickly. So it’s going to be a big change.
How did you find the process of automating publishing production?
It’s really great. I mean, one of my former coworkers and I tried to do this on our own without any software to see if it was doable and it took forever, and it was not actually as doable as we thought. We could do Word to XML and then XML to HTML, but it took a very long time and a lot of effort.
So automating it and just working with the two vendors was just really great to see how quickly it went and then, you know, it does require your XML to be perfect, but when it is, it works great and it’s so fast. That was really great, a relief, and now I just have to focus on our authors and not the process.
Do you have any advice for people looking to do something similar?
What I wish I would have done first was to really take a good look at what we had. I knew that we wanted to start with these high-impact computer security publications, because they are definitely our most utilised, downloaded and re-used publications. But I didn’t really pay as much attention to the Word documents as I should have before I started.
I think maybe cleaning them up with the authors at the beginning probably would have saved some time because now we might have to do it at the end, after we’ve set up the conversion process. The processes are in place, so that won’t be a problem, but I think if I had to do it over again, I would have started with making those Word documents perfect at the beginning.

Kathryn Miller
Publishing Services Librarian | NIST
The National Institute of Standards and Technology (NIST) promotes U.S. innovation and industrial competitiveness by advancing measurement science, standards and technology in ways that enhance economic security and improve our quality of life. NIST is a nonregulatory agency of the U.S. Department of Commerce.
Kathryn Miller’s work at NIST includes coordinating the production, dissemination, marketing, bibliographic control, and impact assessment activities related to the publishing of the Journal of Research of NIST and the NIST Technical Series Publications.
Kathryn holds a master’s degree in library science with a focus in archives, records, and information management from the University of Maryland at College Park. She is also a certified Library Carpentry instructor and holds a Certificate in User Experience in Libraries from Library Juice Academy.