Learn how to go from unstructured Word manuscripts to perfect PDFs in minutes—no human intervention required!
eXtyles Arc by Inera is an automated solution that intelligently structures raw author-submitted Word files and produces semantically rich JATS XML.
Typefi is a global leader in single-source automated publishing, leveraging the power of XML and the professional design capabilities of Adobe InDesign Server to enable rapid, multi-format publishing without compromise.
Together, Inera and Typefi are an unstoppable force for automation good, helping publishers, preprint servers, and repositories produce high-quality XML and PDFs more quickly and consistently than traditional methods, at a lower cost.
This webinar, recorded on 17 June 2020, demonstrates the automated eXtyles Arc process—from unstructured manuscript files to richly tagged and valid JATS XML—and how Typefi enables users to take the XML and produce high-quality print or web PDFs in a matter of seconds!
Typefi and Inera have extensive experience helping scientific and scholarly publishers to dramatically streamline print and digital workflows. Explore our Industry Solutions pages and the Inera website to learn more, or drop us a line if you have questions about this webinar or if you’d like to have a chat about your publishing needs.
Transcript
| 00:00 | Introduction |
| 00:45 | Session overview |
| 01:54 | About Inera eXtyles Arc |
| 08:36 | About Typefi |
| 11:08 | Demo: Raw Word manuscript to JATS XML with eXtyles Arc |
| 23:25 | Demo: JATS XML to PDF with Typefi |
| 28:27 | Q&A (Read the extended Q&A on the Typefi blog) |
| 38:53 | Conclusion |

Emily Johnston
Typefi

Jamie Brinkman
Typefi

Bruce Rosenblum
Inera

Liz Blake
Inera
EMILY JOHNSTON: Welcome to the webinar, everyone— end-to-end automation with eXtyles Arc and Typefi. This session is co-presented by Inera and Typefi Systems.
I wanted to start by introducing who the speakers are going to be today.
My name is Emily Johnston, I’m Director of Business Development for Typefi Systems. Also presenting for Typefi is Jamie Brinkman, who is a Senior Solutions Consultant for Typefi.
And on the Inera side we have Bruce Rosenblum, who is VP of Content and Workflow Solutions, and Liz Blake who is Director of Business Development.
Session overview (00:45)
EMILY: Let me start with an overview of the session today. In this webinar we’re going to talk about, and then demonstrate, how you can take a raw, unstructured manuscript file, and use eXtyles Arc to automate the application of structure, resulting in an enriched, fully tagged XML file. In this case, that XML will be in the JATS XML format.
We will then show how that JATS XML can be input into Typefi, which will automate the layout of the content, producing a PDF for print or web distribution.
So, we’ll start with an introduction to Inera and eXtyles, which Liz Blake will present, and then I will give a brief introduction to Typefi.
From there, we’ll move on to the demonstrations, where Bruce will demonstrate eXtyles Arc, and Jamie will demonstrate the use of Typefi.
And then at the end we’ll circle back with the questions, the Q&A section.
So, at this point, I’m going to hand it over to Liz, who is going to talk about Inera and eXtyles Arc.
About Inera eXtyles Arc (01:54)

LIZ BLAKE: Thank you everyone for joining us today.
I just want to give everyone an overview of our organisation and our technology, and talk a little bit about who we are, what eXtyles Arc is, and how it fits into a Typefi workflow.
Inera has been around since 1992, and actually almost exactly a year ago, we became a part of Atypon Systems.
Our team is really made up of, on the one hand, software developers, and on the other hand, publishing professionals, so in addition to a lot of technology people, we have people with a great deal of experience in editorial and production departments within scholarly and technical publishing.
Our primary goal is to develop tools and systems for publishers to use to facilitate the efficiency of their workflow and to enable single-source publishing from XML.
Our tools actually work primarily within Microsoft Word, and then can transform Word documents into XML which can be used for multi-format publication, which we will talk about in more detail later in the demonstrations.
We try to apply industry standards wherever we can. And that’s something that, again, we’ll also be talking about—things like JATS, DOI and ORCID will come up in the conversation, and we always try to make use of those standards in the tools that we provide to publishers.
eXtyles is our flagship product, and actually it’s celebrating its 20th anniversary this year, so it’s been around for a good long while. And as I said, eXtyles works within Microsoft Word.
It is a suite of tools designed to automate as much of the editorial process as possible. And it really has three primary goals.
One is to normalise the formatting and structure of a document. The second is it can be used to automate a certain amount of editorial style application and consistency in the document.
And the third thing that it does is generate enriched full text XML directly from Word, and we can do that according to JATS or other DTDs or schemas. As Emily mentioned earlier today, we’re going to be talking about JATS and showing you some JATS XML.
The real important design principle of eXtyles is that it’s designed to work with real world author submissions, so we’re not relying on the author to apply a lot of structure to the document that we can use to create a tagged XML file. We’re not even really relying on the author to follow your editorial style.
We’re assuming that the author’s manuscript is going to come in without a lot of semantic information applied to it, and that it may not follow the style that you prefer to use in your publications, and eXtyles is really designed to work with that.
Because authors, of course, are subject matter experts and they’re not publishers, and nor should we expect them to be.
And so one of the things, although our tools are really designed to help publishing staff work more efficiently and automate the less interesting, more repetitive, more time consuming aspects of document preparation, is that they’re also a boon to authors because it frees the authors up to focus on what they really want to focus on, which is research and writing.
And one of the key things that we do not require from authors is the use of publication-specific formats or templates. So again, we’re not assuming that the author is going to apply any structure to the document.

Instead we provide tools within eXtyles to provide document structuring. So, on the left we can see, for example, a Word file, and in the screenshot you can see what we call our style palette.
For those of you who are familiar with Word paragraph styles, we do make use of them. And we have specialised tools for applying styles to a document to semantically identify document elements, whether it’s an article title or an author list or an abstract or so forth.
In the second screenshot you see here, there’s also colour that gets applied to the Word file, and that’s actually the automated application of Word character styles. Name styles in this case, in references, which are identifying not only this is a reference, but also identifying this is a reference number, this is a reference author surname, author initial, and so forth.
So, within the familiar Word environment, we’re actually making use of Word tools to apply a lot of structure to the manuscript. And again, eXtyles is doing this on a manuscript that comes in without any structure applied by the author.
So, what is eXtyles Arc? eXtyles Arc is actually a new product that we announced about a year ago, and it is the latest innovation in eXtyles technology.
In a traditional eXtyles styles workflow, most of the tools are automated. And, in fact in the previous slide, all that colour that I showed you in the references, that’s all automatically applied by eXtyles.
But some aspects of the eXtyles feature set have always required some manual intervention, in particular, the application of Word paragraph styles and the structuring of the document.

So, what eXtyles does is takes the manual intervention part out of that workflow. Arc provides a completely automated system to take you directly from that author submission to enriched full text XML with no manual intervention.
This is a way to get completely hands-free publishing. This workflow diagram on this slide is one that’s really already in place with a lot of joint customers that we share with Typefi, with the difference being the inclusion of eXtyles Arc in that second slot, rather than the traditional eXtyles software.
The traditional eXtyles software requires some manual labour, but with Arc, from Word file to all of your beautiful multi-format output, it can all be done in a completely automated fashion with no manual document preparation.
So, it’s a really exciting new workflow, and we’re very excited to be able to share it with you today and go into this with a bit more detail during the demonstration. Thank you, Emily.
About Typefi (08:36)
EMILY: Thanks Liz. So, I wanted to give an introduction to Typefi.
Typefi was founded in 2001 and is headquartered in Queensland, Australia, but we do also have offices in the US, the UK, the Netherlands and Sri Lanka, supporting thousands of users in over about 35 countries worldwide. We are an Adobe Technology Partner.
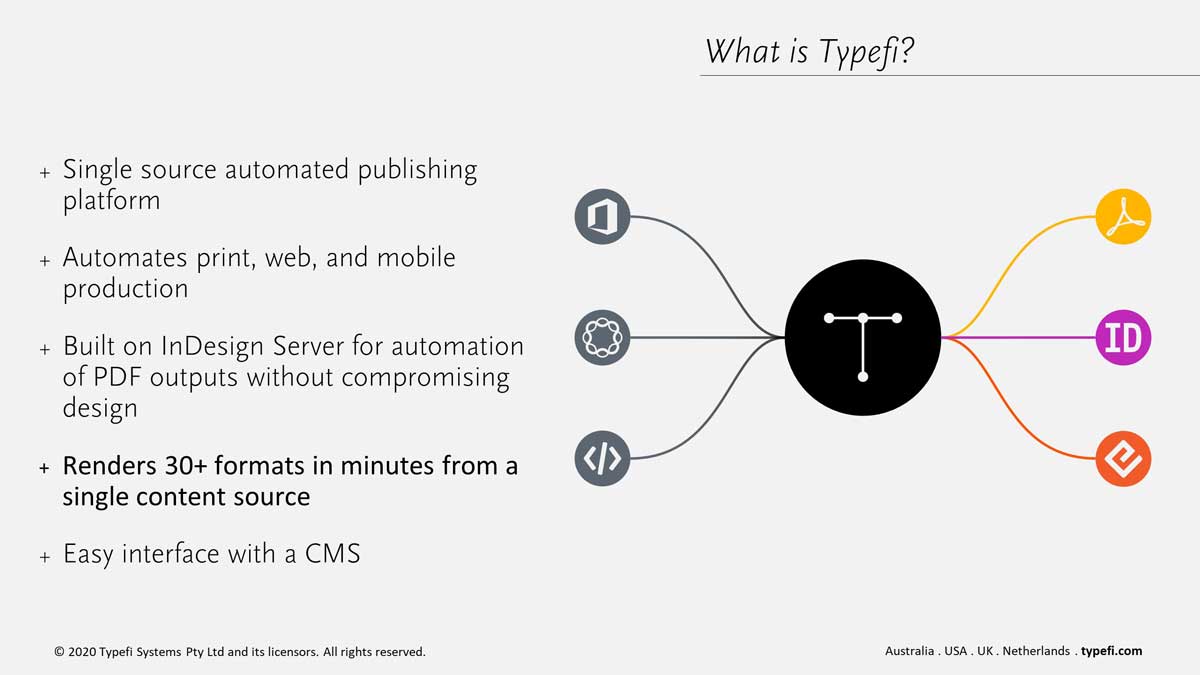
So, what is Typefi? Typefi is a single source automated publishing platform that allows users to input their source content, which in this case would be the JATS XML created by eXtyles Arc, and automate the creation of print, online and mobile products, all in a matter of minutes.
For the creation of a PDF format specifically, which is what we’re going to highlight and show in the demo today, Typefi automation is built on top of Adobe InDesign Server, which allows for the creation of high quality PDF outputs without compromising on design.
PDF outputs are not the only option, as I mentioned, Typefi automation can be configured to produce more than 30 other formats for print, online or mobile distribution. And again, that’s all from that single source XML file created by eXtyles Arc.
So I just wanted to highlight what some of the benefits are that our customers have seen using Typefi. Our customers have seen significant time savings, as is the case with the International Monetary Fund who was able to save about 80% of their production time, and decrease their time to market from weeks to days.
One other example is IGI Global, who was able to achieve higher production volumes. They were able to nearly triple the number of books and journals that they were able to create using an automated Typefi workflow, and they were able to accomplish that without the need to add any additional staff.
So, that’s a brief introduction to Typefi, and at this point what we’re going to do is move to the demo section of this. So, I’m going to hand this over, and Bruce is going to give the demonstration of eXtyles Arc, and then Jamie will give a demonstration of Typefi.
Demo: Raw Word manuscript to JATS XML with eXtyles Arc (11:08)
BRUCE ROSENBLUM: To run this demonstration, we’re going to start with this Word file, which is as it was submitted to the publisher, just a raw author manuscript. We haven’t touched this at all.
You can see it’s got typical front matter of a document, the abstract following the authors and affiliations, the introduction and method sections.
And if we skip to the bottom you can see we have a couple of tables, we have a figure caption, we’ve got a reference list, and we’ve got acknowledgement. So, the typical structure of a scientific document.
And if we switch over to draft view, you can actually see that there’s not only no useful paragraph styling information in here, things like Body Text and Normal, but in fact, in a few cases, we have paragraph styles that might almost throw us the wrong way if we were requiring paragraph styles for setting things up.
So, one of the important points to reinforce about this is we don’t need any template used by the author, we don’t need any paragraph styles, we literally take the raw author document just as it was submitted by the author.
So, once we have this document, what we do is we switch to our eXtyles Arc server, and this is a service that runs in the cloud. We can select our input document, and we’re just going to run it as a full text extraction to JATS, meaning we’re going to convert this whole file over to JATS and we’re not going to apply any editorial clean-up rules.
What we can do, however, is set up some metadata for the document on this form. So, this is a document that was published by the World Health Organization in the Bulletin of the World Health Organization. We have the Journal ID. This is a research article, we have the Article ID, and this is metadata that will ultimately appear in the XML.
And we have a variety of other ways of processing metadata, but let me now, with this document and with this metadata, kick off the process.
And you’ll notice that I’m actually running this process in our user interface, but everything that I can do in this user interface, plus more, is fully enabled in the API that we have. So, this can be called as a machine-to-machine process for a really highly automated workflow operation.
You can see that what we’ve now done is set this job to Running. We have a maximum time of five minutes, although most jobs finish in about half of that time.
And what’s going on under the hood now, is we actually have a server-activated version of eXtyles, eXtyles SI, running with our eXtyles Arc technology, it’s now processing this document.
So, what it’s doing is a sequence of steps, where first of all, it’s going through and automatically identifying all of the semantic components of the job.
So, where in the Word document you saw that we had authors and affiliations and the title and keywords and so on, all of which didn’t have any useful information to say semantically what they are, eXtyles Arc is automatically going through and identifying each of those paragraphs.
We’re then within certain paragraph types, such as the authors or, most importantly, the bibliography, we’re using additional pre-existing eXtyles technologies to peel those paragraphs apart into their itty-bitty pieces.
So, with the authors, we’re parsing those elements into each author’s surname and given name. We’re parsing the affiliation links. We’re parsing roles if they happen to be there, or author degrees.
And then in the bibliography we are, of course, parsing out all of the references into a very high degree of granularity.
We can add other options on top of this. For example, what we aren’t doing today is taking that bibliography and linking it to PubMed or Crossref. That is very easy to add into this workflow.
Or we can add in all of the editorial controls for which eXtyles is well-known. So, we can add our auto-redact feature, we can add reference clean-up, we can add PubMed correction, and so on.
So, these are all options within this workflow, but today all we’re focused on is taking this Word document and doing a very direct conversion of the exact content that the author gave us to very high quality, hierarchical and granular JATS.
And you can see at this point that the conversion is done, and we can now download this package. And, again, if you were using the API, you would actually have the package come back to you automatically.
We can open this up, and you can see what comes back to us is a series of files. The first is the original Word document that was pushed up, so we give that back to you in the output.
The second is the document that’s been processed through eXtyles, and for those of you who are familiar with what eXtyles can process in a document, or what it can do to a document, this will look familiar.
So, we’ve marked up the authors with character styles. We’ve added Word comments to the file. Click the eXtyles ribbon, and you can see that we’ve added Word comments, for example, a table that was called out in the document that doesn’t exist in the document.
We’ve marked up the in-text citations with character styles, and then we have, of course, the reference list with all of its markup. And, again, warnings wherever we see problems, such as an illogical page range that would need to be addressed by an editor.
And, of course, something like this page range problem can actually be addressed automatically by the automated PubMed correction feature that we have.
The other thing you’ll notice is that, whereas our Word document before, I’ll switch to that for a moment, started with no useful style information, the output document actually has every paragraph identified with its correct semantic style.
And so this is the key to making all of this work, is we’ve written an AI-driven engine that allows us to go through the document, and automatically read the document almost as though it were a human reader, to identify all of the elements.
And the result of this is a JATS XML file that was created with absolutely no manual intervention between the Word file we sent in and the output JATS file, that is exactly what you would need to go on to the next stage of your production.
Whether it might be copyediting in an XML environment, whether you might just literally take this file and push it straight through into production. That’s really up to you, and your specific workflow.
But you can see that we have filled in the metadata that we collected early on, the name of the journal. And, actually, from the journal name we provided, we were able to fill in the additional abbreviated forms of the name, as well as the ISSNs.
We have the publisher, we have the publisher ID, we have the article type.
And we also have much richer controls for incorporating metadata from third-party sources into this workflow. What I’ve been showing today is just the simplest form, but we have multiple ways that we can incorporate your metadata.
As we move into the author list, you can see that this is all very richly-tagged in the authors, and linked to each of the affiliations. The affiliations, you’ll note, are sub-parsed into each of their component pieces, departments and zip codes and countries and cities.
We have the correspondence, which is actually linked by this corresp=”yes” attribute to the corresponding author paragraph, even though the Word file did not actually have any kind of a footnote linking symbol linking this paragraph to the corresponding author.
So, once again, eXtyles has been able to automatically make those linkages in the resulting XML.
As we come into the body of the document, you’ll see that we’ve— ah, actually, even before the body, with the abstract, we’ve sectionalised the abstract. Again, in the original file we just had bold running heads, so we don’t need anything special done, but we’ve automatically picked up the sectionalised abstract and marked that.
We’ve demarcated all the keywords, again without any special markup in the Word file.
As we get into the body, you’ll see that we have all of the cross-references to the references list marked up, we’ve set attributes for section types, which are often used for building online tables of contents.
We have the table that was at the end of the Word document embedded just after the paragraph where it was first called out, and the table itself is very attribute-rich, with not only things such as column and row spanning information, and vertical and horizontal alignment, we even include scope attributes for Section 508 compliance for those of you who are concerned with accessibility.
So, this is very very rich XML, and it is fully compliant with the deposit rules of PubMed Central. So, this is XML that you can take and immediately go and move it forward in your publication workflow, you don’t have to do additional markup by hand.
And, of course, finally we have in the reference list such rich, heavy tagging that it’s actually hard to read the content of the individual references.
In addition to this, we have a log file that actually logs all of the actions that were taken by eXtyles Arc, and with each item we log not only the date and time, but a class and a specific number of each action.
The numbers are all unique so that you can actually have a system that evaluates the logs and figures out if there might be something that might need manual intervention, such as a large number of errors in one particular process in the file because the other just didn’t do something correctly.
And then, of course, we have human-readable messages along with the machine-readable numbers, so that a person can act on this as well as a machine.
So, ultimately what we have is a very rich output that has everything you need – the original Word file, the processed Word file. Of course, most importantly, the very rich JATS file, and a log file indicating everything that went on.
Finally, I want to point out that this is incredibly flexible in terms of your workflow. If, for example, you have a workflow where you’d like to have all of the eXtyles processing done upfront, and then use the resulting output Word file for copyediting, you can actually do that.
And then, after copyediting is done, we have a separate workflow where you could then upload this file back to the server, back to our eXtyles Arc server, and we could do just an export from the previously processed Word file.
So, there’s a huge amount of flexibility in terms of the workflows, even that we offer out of the box, as well as custom workflows that we can create, so that you can ultimately get exactly what you’d like with eXtyles Arc.
Now, of course, that’s only half the fun! Once we’ve done all of that, we can now hand the file off to Typefi for automatic PDF creation. From here I’m going to hand it off to Emily Johnston of Typefi, and she can take it from here and tell you about that part of the process.
EMILY: Thanks, Bruce. Now that we’ve seen how you can use eXtyles Arc to take a manuscript file and create JATS XML, we’ll next see a demo of how you can use Typefi to automate the layout of that JATS within InDesign to create a PDF.
Jamie Brinkman is a Senior Solutions Consultant for Typefi, and she will show us that process. So, at this point, I will turn it over to Jamie.
Demo: JATS XML to PDF with Typefi (23:25)
JAMIE BRINKMAN: Thanks, Emily. All right, what we are looking at right now is the Typefi web interface.
In an automated solution you might or might not be actually using this, because we can also plug into a content management system and work that way. But, just for the purposes of our demonstration, that’s what we’re using right now.
And in this web interface you can see we’ve got some different folders that contain the different pieces of the puzzle. So, we have the content folder, which that’s where we’ve got our JATS XML, we also have images and our InDesign templates stored, and we also have what we call a workflow.
So, a workflow is basically a series of steps, or actions, that tell Typefi what to do. So, in the case of this workflow, which I’m going to go ahead and run really quick— grab that XML file and run it.
All right, so while that is running, this workflow has a series of steps that starts out and it takes that JATS XML file and then converts it into what we call CXML, which is the XML file that has all of the paragraph styles and different design things added in.
And then, of course, we’re bringing in the fonts, and then we’re running that file through InDesign, and exporting a PDF. So that’s a pretty straightforward workflow.
And then, when that job is completed, then you’ll get your InDesign file and your PDF prepared for you. This should be done in just a second, there it is.
And so now you can see that it was a pretty quick job, and it gave us all of these files. So I’m actually going to— I’ll go ahead and download the InDesign file for looking at, and then in the meantime I’m opening up the PDF that we just generated.
So, this is the PDF that we just created based off of that JATS XML file, and you can just see it’s a pretty standard PDF, pretty standard layout. The look of this layout, of course, is completely controlled by your InDesign template.
Here’s the InDesign file that we just generated. We can actually see all of the content, of course, in the InDesign file, and you can also see— let me zoom in just a little bit more here— you can see this boxes here that have a label on them, and they have a colour border.
These are some of the aspects of the automation that Typefi has added into InDesign, and that is that we have different elements and different zones for the content to go into, so then different content can be placed into the appropriate sections.
So you can see we have, for instance, an abstract, and for the article title, and then just the main flow of the content, of course.
And then we also have, for instance, graphics and tables, and you can see that they are called out at points in the content, and then the engine will place the table as close as it can to the point when it was called out. It just basically goes through and lays out your entire document.
All of the font styles, the rules for how these different tables and elements can place, you know, if they place at the top of the page or the bottom, or just alignment, things like that, all of that is controlled in your InDesign template, so you can make it look however you want it to look. You have complete control over that.
So that’s the basic process.
And, another thing to note is if you want an accessible PDF we can also support that. If you pass alt text through from your XML file, that can be plugged in, and we can also design the InDesign template to support all of those features.
So all you have to do is, once we’ve designed the template and the XML runs through, then you’ll be able to get an accessible PDF if that’s what you need.
Typefi can also be used to create additional types of output. You know, you could create EPUB, or HTML, or whatever you needed.
Q&A (28:27)
EMILY: All right. Thank you, Jamie.
So now we’ve had an opportunity to see how you can take a raw manuscript file and transform that into XML using eXtyles Arc, and then put it through Typefi to create a PDF output.
At this point, we have about 10 minutes left in the webinar and wanted to open it up so that we can answer some questions. So, Sylvia, do you want to share any questions?
SYLVIA IZZO HUNTER: Sure. The first question I’m seeing is how well does eXtyles Arc handle complex tables in Word files?
BRUCE: Thanks Sylvia. I’ll take that one. It handles them quite well. So long as the author of the document has used the Word table editor, we can pick up spanning rows, spanning columns. We can even pick up things like decimal alignment if the author has used that, so the table will really come out very, very well in the eventual PDF that’s created.
And as I noted during the demonstration, we’ll also do some enrichment in terms of things like adding scope attributes automatically so the tables are 508 compliant.
So we handle tables that are definitely more than just a simple X by Y grid. Make them as complex as you want, and we can handle it.
SYLVIA: Thanks, Bruce. And I think this is probably for both Inera and Typefi. Do you have any examples of how this works with more complicated content like math and chemical formulas?
BRUCE: I’ll go first and then Jamie, if you want to answer from the Typefi end.
In terms of math, most authors will generally use either MathType or the built-in Word equation editor, the equation builder that was introduced in Word 2007. And so long as the author has used one of those two tools to create the math, eXtyles automatically converts those to MathML. And if you have a custom workflow, MathType can also be converted to LaTeX.
Jamie, do you want to talk about how Typefi handles that?
JAMIE: Yes. Thank you. So, once the MathML is present in the XML, then we have a couple of options for how we can display that. We can display it as live editable text in InDesign using a plugin called MathTools.
Or we can also, if you have equation images and want to pass those through, then we can also display those, and we have a series of scripts that help control alignment to make sure that all of those align properly with your text and everything looks how it should.
SYLVIA: Great. Thank you. Next question. How can proof corrections be incorporated?
BRUCE: There are a couple of different ways that this can be done. The first is that with eXtyles, we noted that we give back the Word file along with the JATS XML. And so what you can do is go ahead and make corrections in that Word file, run the alternative workflow I pointed out where you create new XML, and then push that new XML into Typefi.
Another option is that you can have an XML editing environment and you make modifications to the JATS XML, so you don’t go back to Word, and then you can just iterate as many times as necessary and push that into Typefi.
SYLVIA: And do we want to hear that from the Typefi perspective as well?
EMILY: Sure, I can take that. So we do recommend following one of the workflows that Bruce had mentioned, making the content changes, within that source file and then running it through Typefi again, especially because the process is so quick.
But if there is a situation where you needed to make a content change or certainly a design change to the proof, you can do that within the InDesign file that’s created by Typefi. So, the end file is fully editable.
But once you do make those content changes within InDesign, it’s divorced from the Word or XML files. So you would need to either roundtrip the content out of Typefi or go back and make those content changes into those source files as well.
So again, that’s why we recommend the workflows that Bruce had mentioned earlier.
BRUCE: Yeah, I’ll actually add one more thing, Emily, which is Typefi really does a pretty amazing job of automating the layout. So I think on those documents, it’s really not necessary to do hand touch up in the InDesign file, and that really helps a huge amount.
Particularly when you’re talking about multi-column layouts, that’s one of the things where I think Typefi really shines, is being able to do a really high quality job on not just a single column layout, but on a two or three column layout as is often found in journal articles.
EMILY: Thank you, Bruce! Absolutely, our goal is to have that generation of that PDF be a hundred percent automated or as close to it as possible, so we would expect to be able to work with you so that you didn’t have to make design tweaks.
SYLVIA: Thank you. So next question. How is metadata for digital content added to the exported files?
BRUCE: I’ll take that. It’s really where that metadata is coming from on the front end, and it can be from a variety of things.
It can be pushed up as additional fields in the API that mimic the fields that were on the form that I showed earlier.
An even better way that we like is if you have metadata coming out of a submission and peer review system, which most of the systems can export XML format metadata, we can then take that and automatically import metadata from that system such as the ORCID IDs that may be associated with author names, received revised accepted dates, article IDs, DOIs, and we can even take metadata from multiple different XML sources.
Once that comes in as part of the upfront processing with eXtyles, we pass that through into the resulting XML and then Typefi can use that for page layout, but it’s also in that resulting XML for any metadata feeds you may need for other organisations
JAMIE: To add to that a little bit. Once that metadata is there and you have your workflow set up in Typefi, we can display that metadata in any number of ways.
We can put it anywhere you want on any of the pages, it can be processed anywhere in the file, and so you have a lot of flexibility on how you would display that.
SYLVIA: Okay, thank you. We have a number of questions about tables, including how are tables that span multiple pages handled, and how are tables that include images handled?
BRUCE: I’ll take the second one and maybe Jamie or Emily can take the first. eXtyles can actually handle embedded images in the Word file and then export them along with the XML coming out of the Word document.
So, we can handle not only images associated with captions, although we do recommend that those be submitted separately because Word can sometimes mess up the resolution once you pasted an image in, but if you have, for example, a table that’s filled with images for layout purposes, eXtyles Arc can also export all of those images, leaving graphic pointers in JATS parlance in the XML.
So, that can all be picked up by Typefi, and so the images will be put into their correct locations.
JAMIE: On the Typefi side, as far as images are concerned, if the images are in the table, then they can be displayed in the table. How that’s controlled is all just down to how you’ve set up your InDesign template and what kind of settings you give it.
As far as tables across multiple pages, there’s several different ways to handle those, and it all depends on the design of your InDesign template and how you wish your content to display.
If a table is an inline table, then it can just flow with the text as one would assume from the name inline—it’s just in the text, and so that can just flow across pages.
If you have what we call a floating table, and that would be something that has text wrap on it so it can be placed in different locations on the pages and the text can flow around it if needed, with those types of tables, if they need to continue across pages, then we can script that so that it just continues from one page to the next.
And we can add continued text, if you need that, saying table continued on next page or continued from previous page, that kind of thing. And we can design all of this based on your input on what kind of design you need.
BRUCE: Sylvia, I want to loop back to one of the other answers I gave, which is around images, because we were talking about if images are embedded in the Word file.
If they aren’t, if you just have figure captions without images, eXtyles Arc will actually put a graphic element in with a standardised naming convention.
And so in that case, if the author has submitted the images external to the Word file, which as I said is preferable, then in that case, the images simply have to be renamed according to the publisher’s standard naming scheme, which we match in the href we put in the graphic element, and then you’re good to go to create the PDF.
SYLVIA: Okay. Emily, do we have time to keep going with the questions?
EMILY: Oh, well, I think at this point what we’ll do is we’ll take a log, write down the remaining questions that we didn’t get an opportunity to answer. And we’ll follow up with you guys individually with answers to your questions, so we can stick to the time that we originally had scheduled for the webinar.
Check out the extended Q&A on the Typefi blog!
Conclusion (38:53)
Thank you so much, everybody, for joining us today. I’ve just put up a slide with contact information.
Again, we will be sharing the link for the video when the video is available, and so that contact information will be in there as well. But if there are any questions, please go back to the original information for the webinar and you can reach out to us there as well.
Your webinar presenters
Emily Johnston
Director of Business Development | Typefi
After graduating from the University of Wisconsin with a Juris Doctorate (JD), Emily’s first job was as a project manager at Apex CoVantage, a publishing services company, where she coordinated production of publications for the American Bar Association. She continued to work in publishing services for 15 years before joining Typefi, and has an in-depth understanding of the challenges that publishers face every day.
Emily works closely with a variety of publishers and organisations in North and South America and Asia to understand their unique needs and recommend solutions that will optimise publishing workflows at all stages of the production process.
Jamie Brinkman
Senior Solutions Consultant | Typefi
Jamie joined Typefi as a Solutions Consultant in 2014, bringing 10 years of experience as a Senior Content Editor with a multinational mass media and information firm. She is highly skilled in layout and design, and has extensive experience in copy editing utilising AP, Chicago, and company-specific style guidelines.
As a Typefi Solutions Consultant, Jamie works closely with customers to develop and implement automated publishing solutions, as well as providing ongoing training and support.
Bruce Rosenblum
Vice President of Content and Workflow Solutions | Inera
With 35+ years of experience designing and implementing electronic publishing solutions, Bruce heads up design and development of eXtyles and Edifix, and works with Inera customers on workflow solutions.
He also consults on the design of electronic production workflows and application of XML in publishing. He developed the Crossref Metadata Deposit Schema, co-authored the original NLM DTD, is an active member of the JATS and BITS working groups, co-chairs the NISO STS working group, and served on the National Information Standards Organization (NISO) Board of Directors from 2005 to 2013.
Elizabeth Blake
Director of Business Development | Inera
Before joining Inera in 2002, Liz was a Manuscript Editor at the New England Journal of Medicine and a member of the task force that transitioned NEJM from a paper to an electronic workflow. Prior to that, she was Managing Editor of Neuron, published by Cell Press, where she was one of the original beta testers of eXtyles.
At Inera, Liz oversees both sales and marketing activities and works with the solutions team to ensure that eXtyles is configured and deployed to meet each customer’s unique requirements.