Many standards organisations adopt and publish standards that are created by other agencies.
In this webinar, Gabriel Powell, Typefi Senior Solutions Consultant, and Bruce Rosenblum, CEO of Inera, show how an STS XML workflow—implemented with eXtyles and Typefi—can simplify and speed up the process of adopting and publishing standards.
The webinar includes a demonstration of how national standards bodies are already using XML to successfully adopt ISO and European standards using a range of input formats, including NISO STS, ISO STS, and PDF.
Transcript
GABRIEL POWELL: Hello and welcome to ‘Standardising the Standards: Working with adoptions’.
My name is Gabriel Powell and I’m the Senior Solutions Consultant for Typefi Systems. I’ve been with the company since 2010, and it’s my privilege today to introduce you to what it looks like to adopt standards.
We also have Bruce with us.
BRUCE ROSENBLUM: Hi Gabriel, I’m Bruce Rosenblum, thank you for asking me join this session. I’m the CEO of Inera Incorporated. I’m also Co-Chair of the NISO STS Working Group.
Inera is located just outside of Boston, and I’ve been with Inera for 20 years, and have been working with standards for a good part of that time.
GABRIEL: In this webinar, we’re going to discuss how national standards bodies can use an XML workflow to simplify the process of adopting and publishing standards that are produced by ISO, and European standards.
That would include the European Committee for Standardization, CEN, as well as the European Committee for Electrotechnical Standardization, also known as CENELEC.
I’m going to begin with an overview of what an adoption is, and then I’ll demonstrate how Typefi and Inera eXtyles are used to facilitate the adoption and publishing process for standards.
Watch: #XML helps national #standards bodies adopt @isostandards & @Standards4EU docs. #XML4standards Share on XSo what is an adoption, exactly? Likely, if you’re watching this, you know what an adoption is, but I’ll begin with a brief overview for those who are unfamiliar with the process.
The International Organization for Standardization, known as ISO, develops and publishes international standards. In fact, ISO has already published over 20,000 international standards. These standards are established within a broad range of industries and business sectors.
A standard is developed through a consensus process, and experts from all over the world work together to develop the standards that are required by their sector. These are really subject matter experts.
Once a standard is developed by ISO, an ISO member country can sell and adopt that standard nationally.
In addition, ISO standards are also adopted and sold as European standards. And a European standard is a document that has been ratified by one of the three European standardisation organisations—that would be CEN, CENELEC, and ETSI.
Let me give you a brief overview of what an ISO adoption looks like.
Here we’re looking at, on the left side, the cover page of an international standard. This happens to be ISO 20160. And then on the right we have an adoption from Denmark. They adopted that ISO file, and let me take you into the core of this so you can see what that adoption looks like in the final published PDF.
This is the Danish Standards adoption of that ISO document. You can see they put their own cover page on this, along with their own designation, which becomes a DS/ISO standard.
If I move through, they’ll have an inside cover page with their own metadata specific for their needs, and then you’ll see the international standard cover shown on the right, and this is the same cover page as the ISO file itself. In fact, it’s the same copyright from ISO, as well as the same table of contents, and body throughout.
You’ll notice that Denmark places their designation at the top in the running header, so that you can see this is a DS/ISO adoption of this ISO standard. But the rest of this document is the same, from every page all the way to the back. Sometimes some national bodies will actually even append their own back page.
So that’s an idea of what an ISO adoption looks like. And if you were going to adopt a European adoption, it would be very much the same, where here we have the CEN cover page and then the actual adoption.
Let me just open up that document.
So here you can see that the Danish Standards cover is here with the designation DS/EN. And moving through, we have the same title page but this time we have a CEN cover with all of the CEN metadata and information. And then the table of contents, and throughout, we have all the content.
So it’s very similar to an ISO adoption, except for the body is from CEN.
I’d like to introduce you to the various input formats that can be used for creating an adoption.
We have three possible methods. One is to use ISO STS XML, and that has been in use for quite a few years now. And many of the standards, since around 2011, are being produced in this format, ISO STS. And then ISO also has gone through and created a back catalogue of XML files, so that would allow you to publish adopted standards for quite a few years back.
Then we have a new upcoming format that Bruce will introduce you to at the end of this webinar called NISO STS XML.
Then, alternatively, some standards just are not available in an XML format, and that would include some CEN standards, and maybe if you’re adopting an IEC international standard. If there is a back catalogue file that you want to publish and you want to use the PDF source instead of the ISO XML source, that’s also a possibility.
Let’s take a look at the pros and cons of the XML input format vs the PDF source input format.
If you’re using either ISO STS or NISO STS as your input format, the workflow looks as follows. On the left you will see that you have several STS XML files. You will have one or more depending on what you are adopting, and I will show you here in a moment an actual XML package.
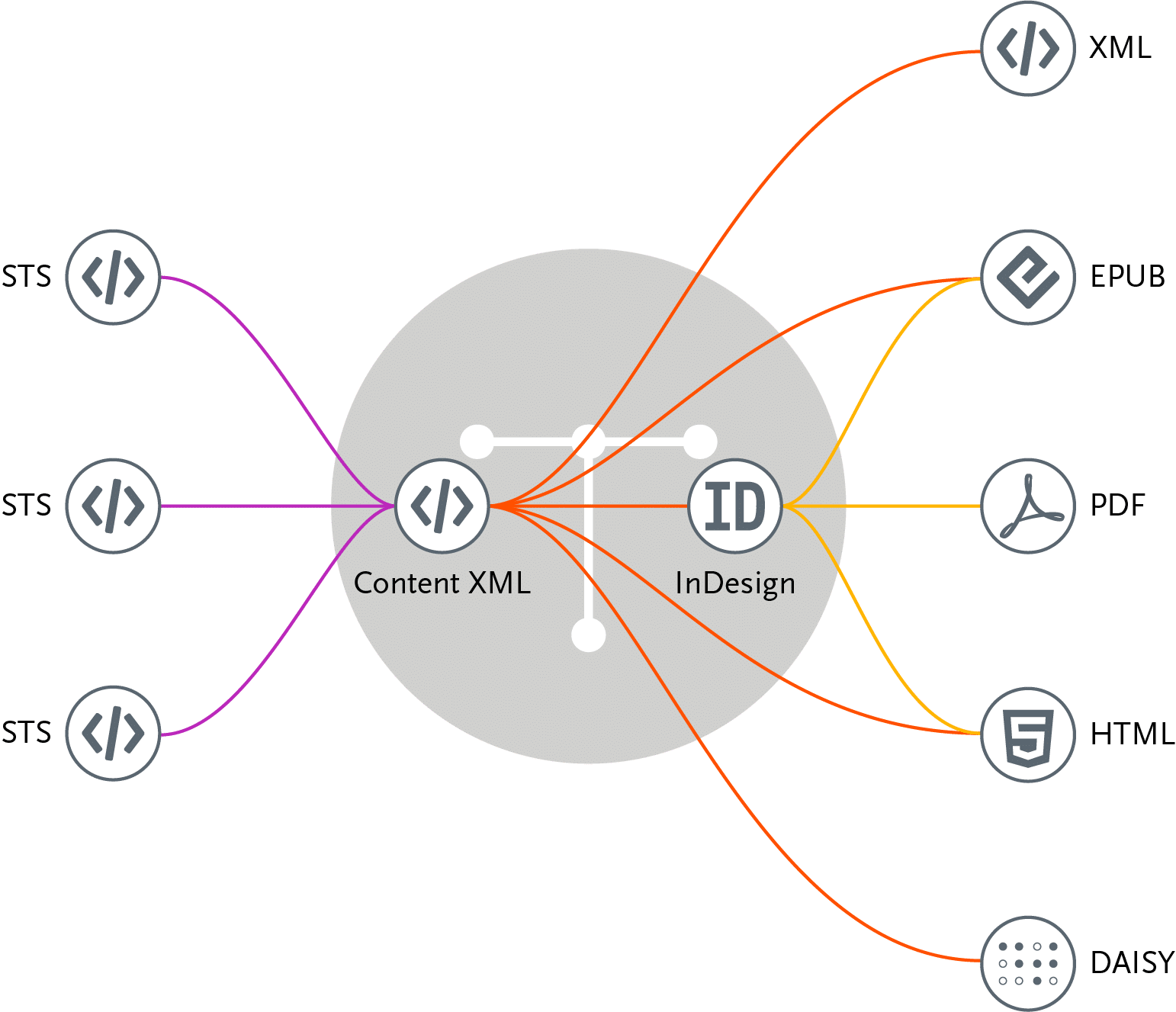
But the benefit of using XML as your input is that you can generate multiple output formats. You can generate EPUB, PDF, HTML, DAISY, and more.
If you use PDF source as a format, you get reliability. You accurately represent that adoption or that standard. However, because you’re using a PDF input file, it is not possible to generate any other output format other than PDF, so keep that in mind.
Let me just move over and I’d like to show you what the input packages look like, comparing an XML input package to a PDF body input package.
So, we’ll begin with an ISO adoption. So inside of an ISO adoption package, this is the input package, notice that we have the original ISO XML file, and this in the ISO STS format.
It has a front section with the ISO metadata, as well as the front matter, foreword, and introduction, the body, starting from the scope all the way to the end of the document just before the annex sections if they exist, and then finally the bibliography.
This is all the original ISO file, and then to create the adoption, all we need to do is create an extra XML input file for the national adoption itself.
In this case we only have a few parts. We have the national metadata section, carrying all that metadata for the national components which includes the metadata for the cover page and the title page.
And notice the body section is empty, because it doesn’t actually have anything. The body is going to come from the ISO input file.
So that is a typical package for an ISO adoption.
Interestingly, it’s also possible to publish a multilingual adoption, so let me show you how that looks.
#XML enables multi-format and multilingual #standards adoptions. #XML4standards #STS Share on XIn a multilingual adoption you would have the same files. We have the same ISO input file with no changes, and then in addition to that we have the Danish standard or the national component, and in this case the body is not empty.
In this case the body has the translated text—so that international standard has been translated into the Danish language and it appears within the XML file from that national body, and that would include every section.
So that’s how we would create a multilingual adoption.
And just to show you as well what that would look like, when we publish the multilingual edition we get two options. One, we have a web-optimised view, and we have a print-optimised view.
I’ll start by opening up the web edition. It starts off like any other standard—we have the national body cover page as well as the front matter—and what makes this web-optimised is that there is a language code to the right of every heading in this document.
If I click on that heading, that language code, it actually takes me to the corresponding language, so that’s a really handy way to navigate between the languages in this document, and you’ll see that all the Heading Level 1 and 2s have a language code, so it’s very easy to compare and contrast and move between languages. That makes this web-optimised.
Furthermore, we have a print-optimised version. And for print, you don’t want to have to read one language before you get to the next language, so it’s really much more convenient to view the languages side by side, and that’s exactly what this print version offers.
You’ll see that the English language is on the left, and the Danish in this case is on the right. So it’s a really handy way when viewing this in print to read this document and compare and contrast along the way.
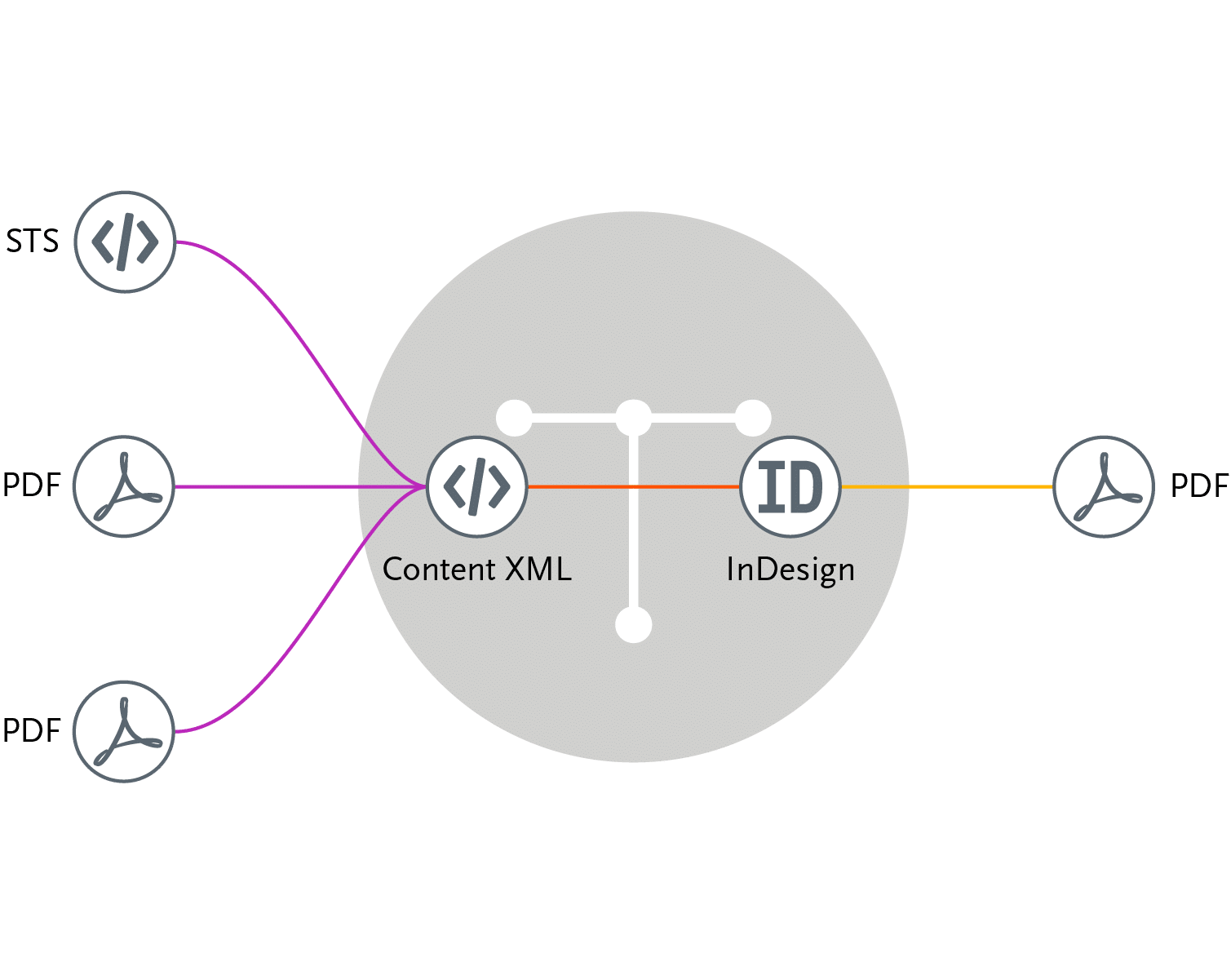
So you’ve seen an introduction to what an XML input package looks like when using ISO STS. Let me show you what an input package looks like when you have a PDF source.
So here is the final PDF output and we’ll take a look at that. I would like you to notice that this PDF, although originates from a PDF source, when you go through Typefi you do not lose the bookmarks. So if bookmarks are in that PDF source file, they’re actually preserved. If the TOC entries are clickable, they remain clickable. So this is a still a web-optimised and highly interactive document, as long as the input PDF file, that source PDF, contains those elements.
So that was the final output; let’s take a look at the input package.
In the input package, you’ll notice that instead of referencing another XML file that would contain the ISO or CEN standard, in this case we have PDF source files, and we have one control file which is what the national body will create.
In this case, Danish Standards has created this. It contains a national metadata section, again used for creating the cover page and their title page.
And then in the body section, instead of actually having XML content to create the body of the document, we have what is called a PDF rendition section, which references the name of the source PDF. And this is referenced in the order that the source PDF file should appear in the output.
It’s really that simple. You just need the control file with a national metadata section and one or more PDF rendition sections, and when you run that through Typefi it will generate the final result, again complete with clickable bookmarks, TOC entries, and hyperlinks.
I’d like to hand it over to Bruce, who will introduce us to how eXtyles is used to facilitate adoptions.
BRUCE: Thank you very much, Gabriel. eXtyles facilitates preparing these adoptions as well. If you’ve already watched the session about getting to XML in this series, then you know a bit about how eXtyles works. And eXtyles can work with adoptions in the same way that you work with preparing a full standard.
What you do, simply, when you’re working with an adoption, is you prepare the front and the back matter of the adoption in Word, and then you convert that to XML. Sometimes that may require having Inera add a few extra paragraph styles to your set in your palette, but otherwise the process works in a similar manner to preparing a full standard.
There are, as Gabriel pointed out, two ways of having the information prepared. The first is to have just your local information in XML, but the standard that you’re adopting in PDF. In this case you would use eXtyles to prepare a Word file with local front matter and your local annexes, and you would use the paragraph styles that have been set up for national standards bodies.
There’s also allowance for various custom metadata elements as necessary, to meet your local requirements for an adoption.
Then you also insert a reference to the PDF file into the Word file, and then you create XML using your standard export processes in eXtyles.
Typefi, as Gabriel showed, can then take that XML and combine it with the ISO PDF, or if you’re a national body adopting a European standard, a CEN PDF, and that all becomes a single PDF in the final result.
You can also do what we call a whole document adoption, where you take the final ISO Word file, you can add your local front matter and annexes to that Word file, and then you can create a single XML file that has your adopted material plus the standard embedded within it, and then Typefi can create a single PDF file from that XML file.
Typefi & @eXtyles enable publishers to easily combine #XML & #PDF in a single output. #XML4standards Share on XAnd now I’ll hand it back to Gabriel and he’ll give a demonstration of how all of this works.
GABRIEL: Thanks Bruce. Now I’d like to demonstrate how we can use Typefi to generate an ISO adoption. And this time I’m going to show off an adoption from Sweden, from Swedish Standards.
Here we’re looking at an input package. This is actually just a ZIP package, I’ve opened it up. In this case we have two input XML files. Again, one is the original ISO XML file, which was produced from eXtyles, and then we have the national XML file and it contains the national metadata section used to produce the cover, and then we have another section which is used on the copyright page.
The body is empty because that content comes from ISO. Then we also have all of the graphics, and that would include the math equations and any figures, and those would be in the package as well.
So to run this through Typefi, I would just need to locate a workflow in the Typefi server, and here you can see a workflow is indicated with this space rocket icon. We’ll produce a web PDF.
This is the actual workflow. I’ll give you a very brief introduction to the components. You have seen this in a previous webinar in much more detail.
It begins by ingesting that input file, so in this particular case there are two parts. One, this component, the SS multi component, will actually unpack the ZIP package and copy all the resources, the images and the XML files, and it will merge those two XML files into one, and then we actually convert those to another form of XML called Content XML using this SS component.
In the end, that input file is passed through a series of actions to create an Adobe InDesign document, and then finally export it to PDF, and finally to update the metadata so that all the metadata is added to the PDF and some other settings are applied to it to make it accessible.
I’ll go ahead and run that workflow. And here I’m just going to choose an input file. And I’ll go ahead and pick up this package, and go ahead and run it.
Now you’ve just watched me manually run a job. It is possible to connect another system on the front end, such as a MarkLogic system, which can actually send the input file via an API connection to Typefi so that you don’t manually run jobs. You can automate the running of the jobs as well.
In this case the InDesign template opens up and you can see all the metadata from that national metadata section showing up on the page to create the cover. And then some additional metadata. Now we’re building the table of contents, the front matter, and now we’re working into the body of the document.
Keep in mind that all the content we see being placed on the page at this moment is coming from the ISO XML input file.
And here you can see the Typefi engine working to apply formatting to all of this XML content, and it’s working out the size of the table, and if tables continue across to another page, even the continuation notice appears automatically.
And at this moment cross-references throughout the documents are being resolved. So wherever you see internal references to tables or figures, those are cross-references, and those are being resolved at the moment. And once they’re resolved, the rest of this document will be very quickly paginated.
Here you can see the rest of the document being laid out. There are various tables and graphics being placed. There are a lot of rules going on here, in fact, there are several keep options that keep figures together so that they don’t straddle a page.
And finally the bibliography and a couple of notes pages are added, and then followed by some static back matter and the back page itself.
So that’s what it looks like to use Typefi to work with an input package, run it through Adobe InDesign, and generate that final PDF which is being created as we speak.
When the job is complete, and you see the green check mark, you can just click on that job and collect all the output. And here you see is the final web PDF that was produced from this workflow.
So now I’d like to hand it over to Bruce, who’s going to introduce you to the new upcoming NISO STS model for adoptions.
BRUCE: Thank you very much, Gabriel. As you mentioned, there is a new model for adoptions in the new NISO STS standard that just came out in October of 2017.
In this model we can have two different top level elements. Previously in ISO STS, we could only have standard as a top level element, and now we can have either standard or adoption as a top level element.
Of course, the ISO STS model is fully backwards compatible with ISO STS, but the new model gives you more flexibility.
NISO #STS offers greater flexibility for #standards #publishers. #XML4standards @eXtyles Share on XBefore we look at the new model though, let’s look at the existing ISO STS model. It’s a relatively flat model. You can have a front matter section with one or more metadata blocks and special front matter sections, you can have one body section, and then you can have multiple back matter sections; for example, ISO annexes followed by your local adopted annexes.
But as a flat model it’s limited in terms of flexibility.
With the new NISO STS adoption model, it’s a hierarchical model. So you can start with an adoption at the top level, you can nest adoptions within adoptions, and then you can have a standard inside of that.
At the very inside portion of this, you can see we have a standard element and that could be an ISO standard. The inner adoption element would be a CEN adoption that has standard document metadata for that standard as well as the CEN annexes just after the standard element.
And then at the outermost level, you could have the national adoption; for example, a Danish or Swedish adoption. And that adoption would have its own standard doc meta element, and its own back matter as well.
Now one of the interesting things about this model is that the back matter for the national adoption could appear just after the standard doc meta rather than after the adopted information.
This gives you tremendous flexibility in terms of representing, in your XML, the reading order, because some national bodies put all of their adopted material up front, and some national bodies have only their metadata up front and their annexes at the back after the adopted material.
Take another look at how this works. This is actually straight from the NISO STS documentation, where you have an adoption with adoption front matter.
And then, in this case, rather than incorporating all of the XML in, you can have a standard xref element that says this is an adoption, that now pulls in by reference an ISO standard.
This is really really cool, and leads to part of the flexibility that we have with this new model for adoptions.
Not only can we include, as shown in the third bullet point, by standard xref, but we can also include standards with XInclude, for those of you who like using that XML model, or you can have the entire standard or, of course, as Gabriel showed before, you can just incorporate a PDF and you could do that using the standard xref model.
So this model that allows multiple inclusion formats is incredibly flexible, because it allows you to have what the working group calls “reading order” XML; in other words, the order in which you prepare your XML file reflects the order in which the content will be rendered into PDF or HTML or whatever reading format you’re going to render it to.
It’s a recursive model, and it allows multiple level adoptions, much much more flexibly than the ISO STS model. And this means that you can have three or even, if necessary, four levels of an adoption as you go through the adoption process.
There’s lots more information about this model. We’ve included two URLs here if you want to learn more. The first one points to the adoption documentation at the niso-sts.org website, and there’s full documentation including some limited examples of how to do an adoption.
The other is STS4i, which is a group that’s promoting best practices for use of both ISO and NISO STS, has a repository on GitHub, and they actually have a sample of a DIN/EN/ISO adoption that shows all of the layering and shows exactly how you can take advantage of this tagging when you’re doing an entire standard as an adoption.
We hope you’ve enjoyed learning about all of this, and I’m going to hand it back to Gabriel now.
GABRIEL: All right, thanks everybody for watching. If you’d like to watch other webinars in this same series, take a look at the URL below, typefi.com/standardizing-standards, and you’ll see a full listing of previous webinars that you might’ve already missed, and upcoming webinars that you might be interested in.
Resources
Presenters

Gabriel Powell
Senior Solutions Consultant, Typefi
Gabriel has been teaching InDesign since 2003 and is the author of Instant InDesign, Creating eBooks with Adobe InDesign CS4 & CS5, and Learn Adobe Photoshop CS4 by Video.
As a Senior Solutions Consultant for Typefi Systems and and CTT+ Certified Trainer, Gabriel teaches InDesign, Typefi, and other applications to creative professionals around the globe. He specialises in automated XML publishing, template building, e-book publishing, and accessible publishing.

Bruce Rosenblum
CEO, Inera & Co-Chair of the NISO STS Working Group
Bruce has more than 35 years of experience designing and implementing electronic publishing solutions. He heads up software development activities at Inera, including the design and development of eXtyles and Edifix.
Bruce also consults on the design of electronic production workflows and the application of XML in publishing. He developed the CrossRef Metadata Deposit Schema, co-authored the original NLM DTD, is an active member of the JATS and BITS working groups, and is co-chair of the NISO STS working group. He served on the National Information Standards Organization (NISO) Board of Directors from 2005 to 2013.
His 16 years of joint work with CrossRef earned Inera and CrossRef the 2014 NEPCo Publishing Collaboration Award.